
The final preparations are underway. All the presents are ready and piled up in a big heap in the Christmas village. Everything is prepared: The reindeer are fed, groomed and have polished red noses (people expect that nowadays). Santa takes one last big meal before the journey starts; after all he needs a lot of stamina to distribute all the gifts. But,... how many gifts are there exactly? Hm, that's a difficult question. Well, there are definitely a lot, but are there a lot, or a lot plus one? Maybe the ELFs should count all the presents, so that no child is left without a present. But how fast can a bunch of ELFs count?
Modern computer systems are massively parallel! There are many CPUs, which could help us count our presents. However, getting the maximum performance out of those cores is actually a hard problem. Today, we will look at one specific aspect of parallel programming: CPU-local data structures.
As you might know, CPUs have multiple levels of CPU-local data (and instruction) caches, which are much faster than accessing the main memory directly. The coarse idea about these is this: on the first memory access (cache miss) the hardware fetches a cache-line worth of memory (usually 64 bytes) into its local Level 1 cache, where all following accesses (hits) are much faster. The difference between an L1 hit and main memory is roughly 2-3ns for a hit and 100ns for a miss.
With multi-core programs, the cache becomes problematic as the hardware has to maintain cache coherence between all L1 caches of the system. If a cache line is not in my local memory, my L1 will try to steal the cache line from the another L1/L2 cache before going to the memory. You can imagine this stealing of cache lines as some kind of message passing between CPUs, which also brings people to the statement that modern machines are distributed systems.
This cache-line transfer between L1 caches is faster than satisfying the miss from DRAM but still takes longer than a hit. Therefore, it is a well-known principle in highly parallel software to keep data CPU-local in order to reduce on the cache-line transfers. One main principle is to use data structures that are cache aware. This means that we should not place data that is accessed by two CPUs within one single cache line as this would provoke frequent cache-line transfers (or in this case: cache-line bouncing.
But coming back to our counting problem. In this exercise, you should explore different strategies to increment a CPU-local counter on N threads such that no increment is lost.
So the first question is: why is this even a challenge? The most primitive version that we can come up with (adapted from operation_regular) has a severe problem:
void count(int *counters) {
unsigned int cpu_id;
getcpu(&cpu_id, NULL);
counters[cpu_id] += 1;
}
As a thread is executed, it can be rescheduled at any point in count and migrated to another CPU. Thereby, the variable cpu_id no longer stores the current CPU id but the id of the CPU where our thread executed before the thread migration. And while this would even be OK if we accept that the semantic of count() would be: Count the counter up, where the function was invoked. However, the main culprit of this scenario is the counters[cpu_id] += 1.
This is a classic example of a read-modify-write problem: We Read the old counter on the previous CPU, Modify the counter value in our CPU register, and Write the modified content back. As we have no control on how the compiler translates our increment operation, we can end up with multiple assembler instructions.
So it is your task to try and benchmark different (correct) alternatives to this broken implementation:
lock: Use a pthread mutex to protect the increment operation on the CPU-local counter, get the CPU id with getcpu(2).getcpu-atomic: Also use getcpu() to retrieve the CPU id, but use an atomic operation (atomic_fetch_add()) to increment the counter.rseq-atomic: Like the previous one, but use the rseq.cpu_id field to get the CPU id (see below).rseq: A full blown rseq(2) solution that increments the CPU-local counter as a restartable sequence. For this part, you have to complete the rseq-asm.S assembler file.With my solution, I see the following scaling behavior on my 16-core Ryzen Laptop:
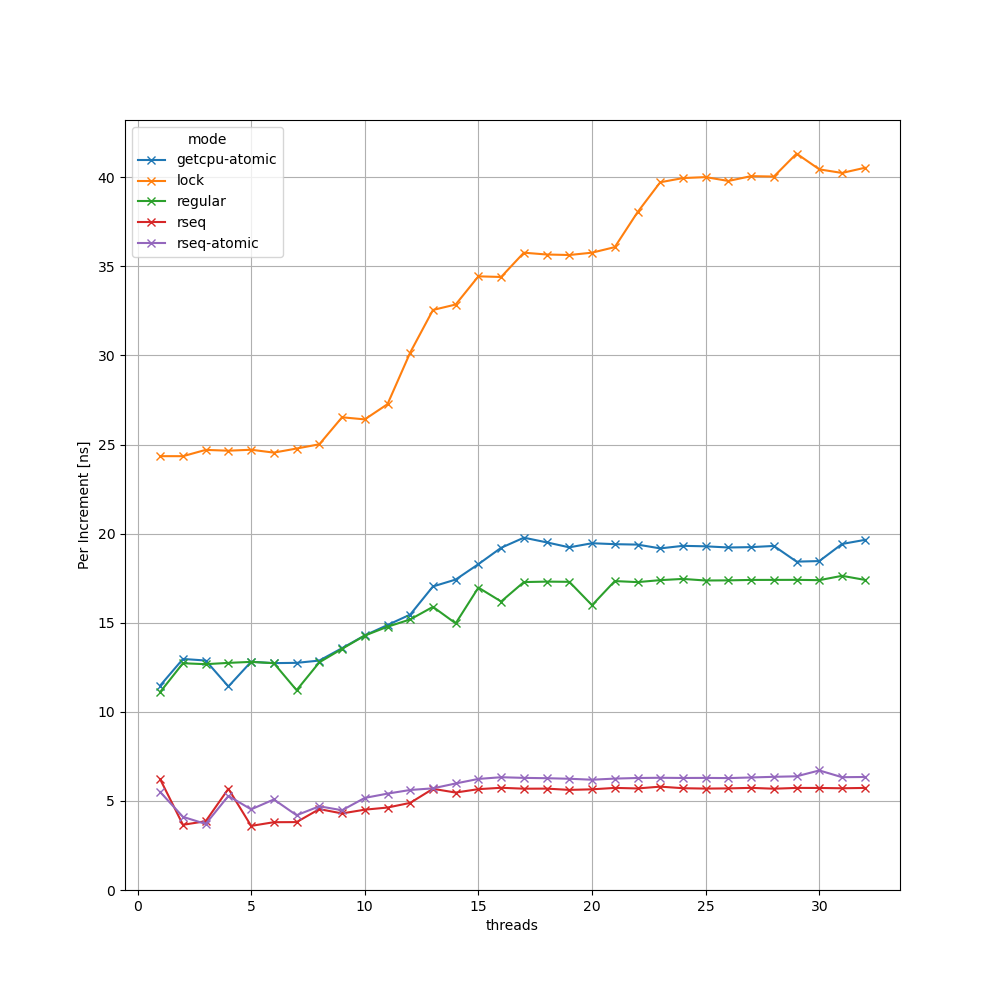
For part 3 and 4, we use the Linux interface of the day: Restartable Sequences. First of all, I want to give you the link to an excellent LWN Article and the rseq(2) man page. The important parts are also explained there. But now, I want to give you a short overview about restartable sequences.
With rseq(2) a user thread can register a struct rseq data structure with the kernel. This data structure has two important fields: Every time, when the kernel migrates our thread to another CPU, it will update the cpu_id field accordingly. Therefore, by reading rseq->cpu_id we always know the id of the CPU we are currently running an. Thereby, we get a faster version of getcpu(), which explains the difference between getcpu-atomic and rseq-atomic in my measurement.
The second part of rseq is much more complex than this: In essence, a thread indicates that it will enter a restartable sequence by setting the rseq_cs field to a struct rseq_cs object, which describes a restartable sequence. A restartable sequence can best be explained by a small assembler example:
start_ip:
mov ...
add ...
mov ...
end_ip:
ret
RSEQ_SIG // A magic marker value in the text segment
abort_ip:
mov...
mov...
jmp start_ip
The restartable sequence is described by three pointers into the code segment: The start_ip and the end_ip pointer enclose the restartable sequence. After setting rseq->rseq_cs, the kernel redirects the user thread to abort_ip if it interrupts, preempts or migrates the thread while the thread's instruction pointer points somewhere between start_ip and end_ip. More illustrative: Assume that the thread currently executes the add instruction. Now the kernel interrupts the thread with a timer interrupt and migrates it to another CPU. Then, the kernel will detect this and will abort the restartable sequence. It will then check (see rseq_get_rseq_cs()) if the 4 bytes before abort_ip are equal to the registered "signature" and will set the thread's instruction pointer to abort_ip.
The big advantage of restartable sequences is that we avoid using atomic instructions when updating CPU-local data as the kernel will detect the critical situation (we are migrated while updating CPU-local data) and informs the user about this. For a detailed discussion about the journey with rseq(), I want to refer you to the EfficiOS blog.
Another thought provoking question for you would be: If we look at rseq and rseq-atomic in the result section, we see nearly no difference between both lines. Therefore, one might come to the conclusion that writing rseq-sequences in assembler is not worth the effort if updating CPU-local data of a cache line in my L1 with atomic instructions is that cheap. But that is a question that I myself have not answered yet.
Last modified: 2023-12-01 15:52:28.194462, Last author: , Permalink: /p/advent-23-rseq